Project Preferences
The first GiDoc entry, 0: Preferences:, opens a window as that
shown in Fig. 2, by which GiDoc preferences can
be set on a transcription task or project basis. There are two buttons
in the top part for project creation or load. The main window area, in
the middle part, is divided into four tabs: Project,
Preprocessing, Training and Recognition.
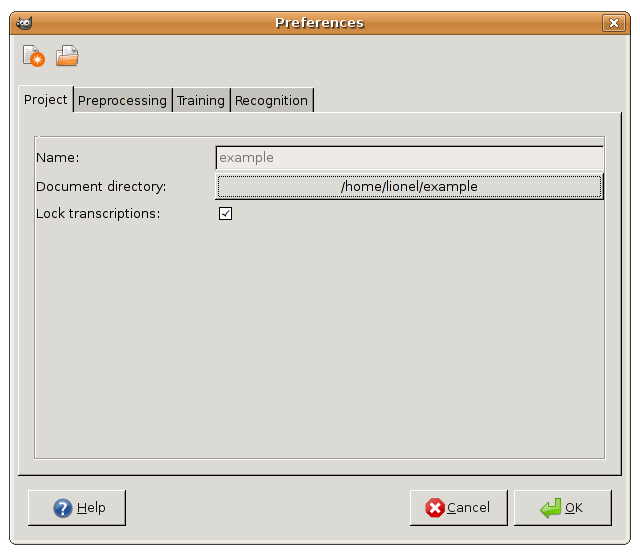
As shown in Fig. 2, the Project tab
consists of three items:
- Name. The project name is mainly used to define a
directory under the global GiDoc preferences directory,
"$HOME/.gidoc", where all project-specific information will be
saved.
- Document directory. Apart from the project-specific
directory defined above, an independent document directory is
defined here where GiDoc will look for (handwritten) text
images. It is assumed that they are saved in GIMP's native XCF file
type.
- Lock transcriptions: If enabled, a warning appears when
trying to modify the page transcriptions.
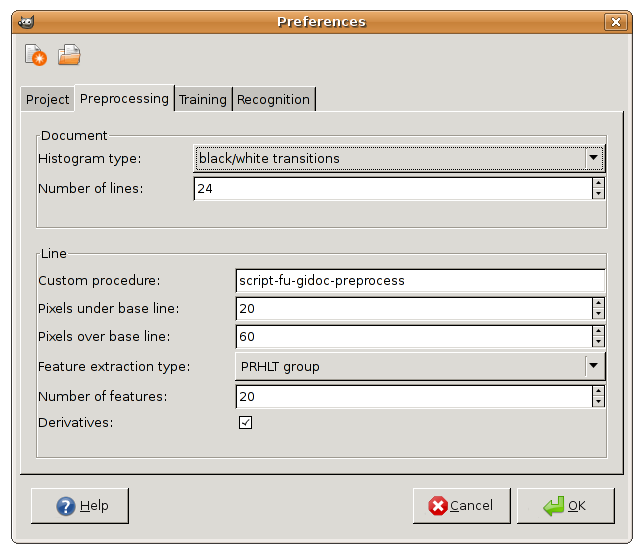
As can be seen in Fig. 3, the
Preprocessing tab includes preferences for both, document and
line preprocessing. Document preferences comprises two items:
- Histogram type. Line detection is based on a rather
standard projection-based method in which horizontally-averaged
pixel values or black/white transitions are projected
vertically. This option is to decide between pixel values or
black/white transitions.
- Number of lines. Maximum number of lines in a text block.
Figure 3:
Preprocessing tab.
|
|
Line preferences refers to preprocessing and feature extraction for
HMM modelling of text line images. Each text line image is first
preprocessed and then transformed into a sequence of (fixed-dimension)
feature vectors in accordance with the following preferences:
- Custom procedure. Preprocessing of a text line image
highly depends on image quality and user preferences. GiDoc
provides a Gimp script function which implements a rather standard
procedure, though here a different custom procedure can be
specified.
- Pixels over and under baseline. Conventional feature
extraction methods work on a bounding box enclosing the whole text
line image. However, GiDoc assumes that only text baselines are
available, and thus here two options are included to define (bounds
for) the locations of the upper and lower bounding box lines, with
respect to the baseline.
- Feature extraction type. This is to select the preferred
feature extraction method from the two methods implemented in
GiDoc : PRHLT and FKI. Please see Sect.
![[*]](http://gidoc.sourceforge.net/usr/share/latex2html/icons/crossref.png) for more
details on them.
for more
details on them.
- Number of features and derivatives. These options only
apply to PRHLT feature extraction.
- Image normalized height. This option only applies to FKI
feature extraction.
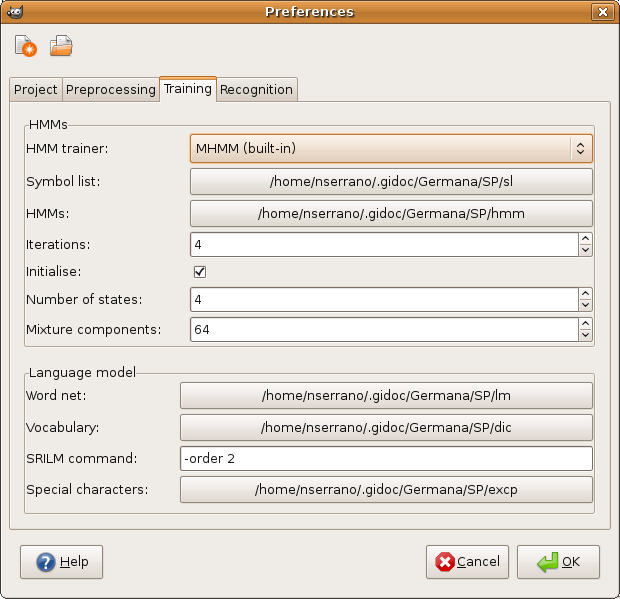
As it name indicates, the Training tab groups all options
related to model training. As shown in Fig. 4,
this tab is divided in two parts: HMMs and language model.
Figure 4:
Training Options
|
|
Options included in the HMMs part are:
- HMM trainer. HTK HMM training software.
- Symbol list. HTK symbol list file.
- HMMs. HTK HMMs file.
- Iterations. Number of iterations performed in each
training step.
- Initialise. If enabled, HMMs are trained from scratch.
Otherwise, GiDoc will retrain previous models.
- Number of states. Number of states per HMM model.
- Mixture components. Number of gaussian mixtures per state.
The language model part includes the following options:
- Word net. HTK language model file.
- Vocabulary. HTK dictionary file.
- SRILM command. Paremeters passed to SRILM's ngram-count
command to calculate the language model.
- Special Characters. File containing characters that split
words in the language model creation.
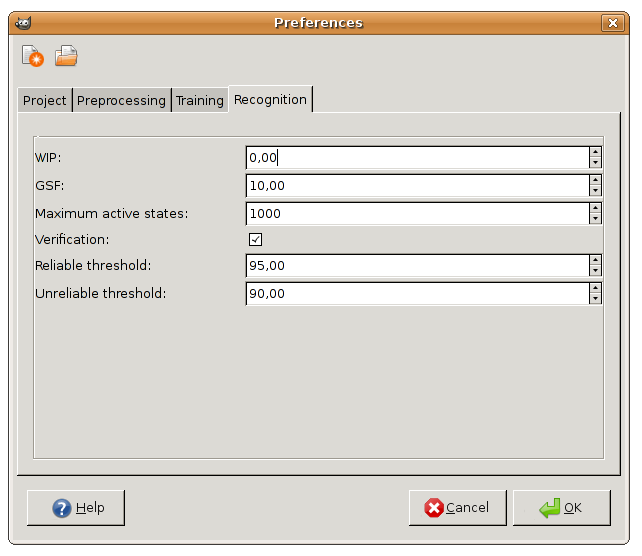
The last tab, Recognition, includes options for both,
recognition and verification (see Fig. 5):
- WIP. HTK word insertion penalty.
- GSF. HTK grammar scale factor.
- Maximum activate states. HTK recognition pruning.
- Verification. If enabled, recognition is followed by
hypothesis verification.
- Reliable threshold. Recognized words with confidence above
this threshold are assumed to be reliable (correctly recognized).
- Unreliable threshold. Recognized words with confidence
below this threshold are considered unreliable (incorrectly
recognized).
Figure 5:
Recognition Options
|
|
giDoc Team