Next: GiDoc First Example Up: GiDoc 1.0 Manual Previous: Training
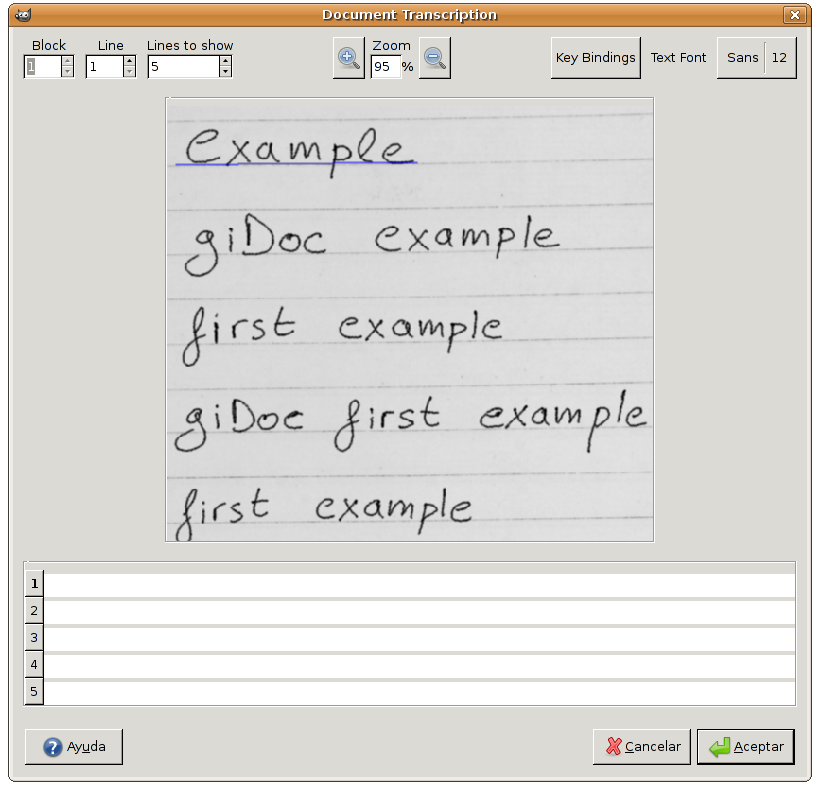
The Transcription entry in the GiDoc menu opens the GiDoc interactive transcription dialog (see Fig. 9). It consists of two main sections: the image section, in the middle part, and the transcription section, in the bottom part. An odd number of text line images are displayed in the image section together with their transcriptions, if available, in separate editable text boxes within the transcription section. The current line to be transcribed or simply supervised is selected by placing the edit cursor in the appropriate editable box. Its corresponding baseline is emphasized (in blue colour) and, whenever possible, GiDoc shifts line images and their transcriptions so as to display the current line in the central part of both the image and transcription sections. It is assumed that the user transcribes or supervises text lines, from top to bottom, by entering text and moving the edit cursor with the arrow keys or the mouse. However, it is possible for the user to choose any order desired
Each editable text box has a button attached to its left, which is labelled with its corresponding line number. By clicking on it, its associated line image is extracted, preprocessed, transformed into a sequence of feature vectors, and Viterbi-decoded using the HMMs and language models trained with Training. The Grammar Scale Factor (GSF) and Word Insertion Penalty (WIP) values to properly combine the HMM and language models are defined in the recognition section of Preferences. Also in it there is an option to adjust the Beam value and thus the computational cost to perform Viterbi decoding. In this way, it is not needed to enter the complete transcription of the cur- rent line, but hopefully only minor corrections to the decoded output. Clearly, this is only possible if, first, text lines are correctly detected and, second, the HMM and language models are ade- quately trained, from a sufficiently large amount of training data. Therefore, it is assumed that transcription is carried out manually in early stages of a transcription task, and then is assisted as described here.
Apart from the image and transcription sections, the dialog shown in Fig. 9 includes a number of controls in the top part, as well as self-explanatory buttons under the transcription section. Regarding the controls in the top part, note that they allow the user to select the current block of the image to transcribe, the current line, the number of lines to show, etc. It is not difficult to configure the dialog so as to fulfil the task needs and user preferences.
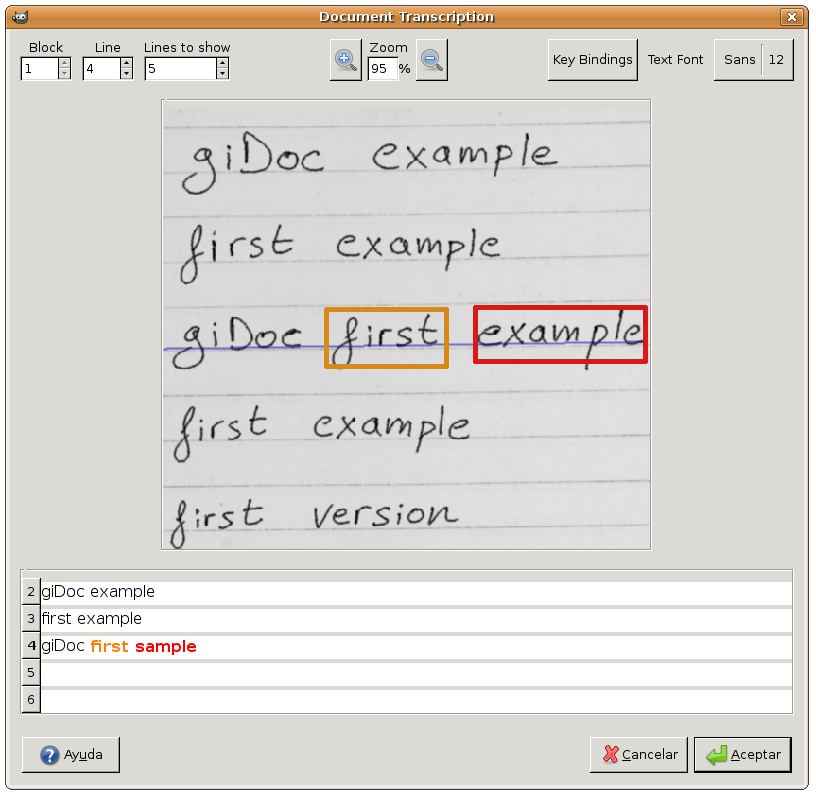
If verification is enabled and the recognition software used is HTK, suspicious words are emphasized in orange (neither reliable nor completely unreliable) or red (totally unreliable). See Fig. 10 for an example. If properly adjusted, verification can assist the user in locating possible transcription errors, and thus validate system output after only supervising those (few) words for which the system is not highly confident. Validation of lines after supervision is done by simply pressing Enter. It is worth noting that only validated lines are used to adapt (re-train) the system trough Training.
giDoc Team